I like the take that they have in that thread: Perforce is forking Puppet into a non-Open Source version (but they’re keeping the name).
Deebster
New account since lemmyrs.org went down, other @Deebsters are available.
- 3 Posts
- 91 Comments
Joined 1 year ago
Cake day: October 16th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.

 4·30 days ago
4·30 days agoBut I said how they work, not, say, how to use a computer to get onto a website. I’m thinking of future generation’s makers and tinkerers, which seemed to be the gist of the article you posted.
The surface of computing is quite polished nowadays, but that’s not entirely helpful when you can’t access anything under the surface to learn what makes it tick.
I feel this article is looking at a bit of silver as if it’s the lining and writing an article about the cloud.
Definitely there’s less knowledge about how computers work nowadays: e.g. universities now have to teach Computer Science students how file systems and directories work, because kids are used to saving everything in the default folder and just searching for what they want (and we’re talking to those geeky enough to be doing CS).
But there’s more complexity now, and a lot of that stuff is just irrelevant busy work. I remember juggling IRQ lines when installing hardware but luckily that’s auto-configured now. I used to create boot discs and eke out enough memory by skipping the better graphics, mouse driver, etc when not needed but did that teach me much?
On the other hand, we used to have LAN parties as teenagers and would rebuild the networking stack for each game, including some performance tweaks (“Red Alert needs NetBIOS over IPX, right?” “Yeah, but disable the turbo encabulator”) and ¾ of us went on to do CS at uni. We certainly never thought of a web browser as “the internet” and we’re confident to explore knowing we could fix what we broke (and did, often).
I think just announce it’s a thing and let people post as they will. I don’t think a daily thread is necessary, for the reason you say but also that individual posts would get more attention - and extra attention is warranted since there’s a lot of extra work that goes in to them.

Perhaps you could run an “advent of vis” where on the first of Jan we post visualisations of our solutions for day 1, etc.
 321·2 months ago
321·2 months agoThat’s the first argument they make in their petition.
 8·2 months ago
8·2 months agoThe oldest known container: github.com/bib/Jonah/Dockerfile
 10·2 months ago
10·2 months agoI’ve been coding long enough that I still think of that as a fairly new thing in JS.
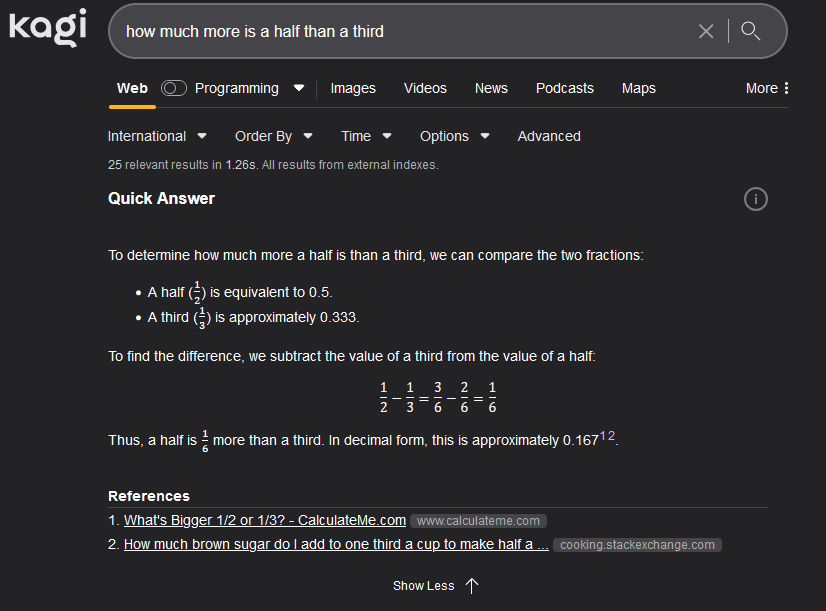
I thought we were finally agreeing fully! My understanding of the question is “what is the difference between a third (of a pizza, say) and a half?”
1/2 - 1/3 = 1/6
1/2 = 1/3 + 1/6
a half is one sixth more than a third.btw, I fixed my Kagi screenshot since I’d missed a word from the question (reading comprehension’s clearly not my strong point today)
Ah, you’re right - I misunderstood jbrain’s point to just be about the “relative to the original” understanding. Guess I’m no smarter than Google’s AI.
Yes, and the Google AI response is correct (and quite clear) in what it says.edit: Thanks Batman. I mean that Google’s understanding of the question is logical (although still the maths is wrong as you say (now I’ve re-read you)) and its answer explained the angle it was answering from.However, I think the reasonable assumption for the intention behind the question is relative to a whole. I had third of a pizza, and now I have an extra sixth of a pizza. It’s subtle, but that’s the kind of thing AI falls down on.
Google’s AI seems dumber than the rest, for example here’s Kagi answering the same (using Claude):
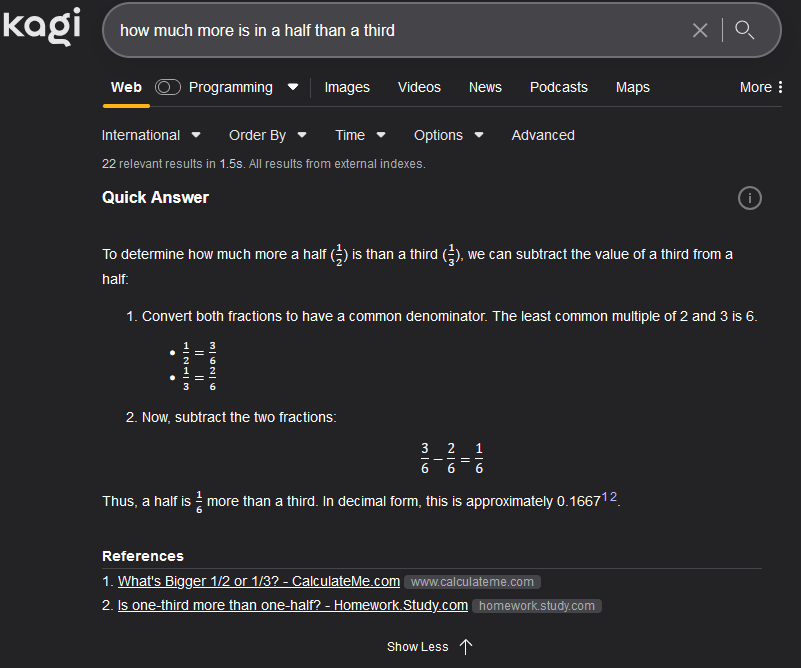
edit: typoed question originallyPerhaps Google’s tried to make it run too cheaply - Kagi’s one doesn’t run unless you ask for it, and as a paid product it’ll have different priorities.
{kind=link}
While I don’t disagree, this article is pretty bad and unconvincing. Is it a draft or something dashed out to collect referral fees?
It shows the top line, so you just read top to bottom (and can scroll if you want).
 1·3 months ago
1·3 months agoMy hope is that something like Servo gets good enough to be included, especially if it’s tree-shakable so you can only include a subset of the codebase. I don’t know if that’s a goal for either projects, but it would be cool - the default webviews can be quite lacking so currently you need to use a restricted set of HTML/CSS/JS to guarantee compatibility.
My (ISO) keyboards do, under the Esc key. I guess you’re in North America (or Australia) and have an ANSI layout.
Token-based string distances looks like exactly what I need for my current side project - I’m using Levenshtein but I should be comparing based on words, not characters.
I just need to figure out which (if any) of these does what I need.
Edit: looks like the Python version has that information: https://github.com/life4/textdistance?tab=readme-ov-file#algorithms
How did you find Leptos to work with? I never got further than the tutorial so I have yet to form a real opinion on it.
It’s a subtle difference between that and
path::exists().path::exists()==falsemight just mean you can’t use it (if path::exists() cannot access a file due to e.g. permissions, it’ll return false)fs::exists()==Ok(false)means it’s definitely not there (permissions error will cause an Err to be returned)
{kind=link}
This might even be an appropriate use for AI (maybe even running in-browser for privacy). I imagine something that reads your prompt and auto-populates a few rings to search. You review and edit the suggested rings, then click search.